

新しいSD用のGUIが登場したので簡単に使い方を紹介します
まだ良くわかっていないことも多いので今回はホントに基本的な使い方だけになります
ノードベースって何だよって話何ですけど、正直上手く説明出来ないので画像を見て下さい
多分何となくわかると思います
BlenderやUnreal Engineでも使う事があります
以前紹介したアップスケールソフト「chaiNNer」もノードを操作するタイプでした
この「ComfyUI」ですがwebUI(Automatic1111)と比べても特別使いやすいわけではありません
むしろ使い難いです
まあずっとwebUIを使っていたので当たり前ですけど
なので既にwebUIを使っている人は敢えて導入する必要は無いと思います
複数のmodelを使用しできたりと機能は良いんですけどね
ただ導入が非常に簡単で起動も早いです
仮に新しいPCでSDを使うならこっちを使うかなーって程度には簡単でした
導入
https://github.com/comfyanonymous/ComfyUI
リンク先の「Direct link to download」をクリックすると7zファイルがダウンロードできるので
それを解凍します
後はrun_nvidia_gpu/run_cpu.batをクリックするだけです
起動は非常に早い上に勝手にブラウザが立ち会ったくれるのも地味にありがたい
ただ画像の生成速度が早い訳では無さそう
公式ページにはギャルゲみたいなチュートリアル動画がありますけど
プロンプトとネガティブプロンプトの事にしか触れていなくて「ComfyUI」の使い方は
ほとんどわかりません
まだ未完成ということらしいですけど
一応(word:1.2)の意味やSDはbad handsを理解していない等面白い話もありますけどね
bad handsは意味が無いと言っている割にはデフォルトのネガティブプロンプトはbad hands
だったりしますけど
使い方
modelは「ComfyUI/models/checkpoints」に入れます
ノード同士は線で繋がっていてドラッグすれば動かせます
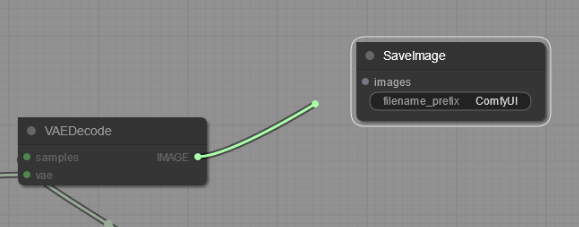
画像はIMAGEからimagesに繋げているところです
少しわかり難いですが対応していないところは灰色なります
あまり目立たないですけど
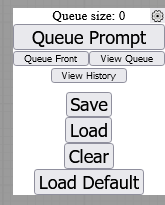
画像生成等はこの部分で行います
- Queue Prompt/画像生成
- Queue Front/良くわからん
- View Queue/良くわからん
- View History/良くわからん
- Save/現在のノードを保存、json形式で保存されます
- Load/保存したjsonや画像をLoadするとノードやプロンプトが表示されます
- Clear/全消し
- Load Default/デフォルトのノードを表示出来ます
txt2img
起動した状態でプロンプトを入力すれば画像が生成出来ます
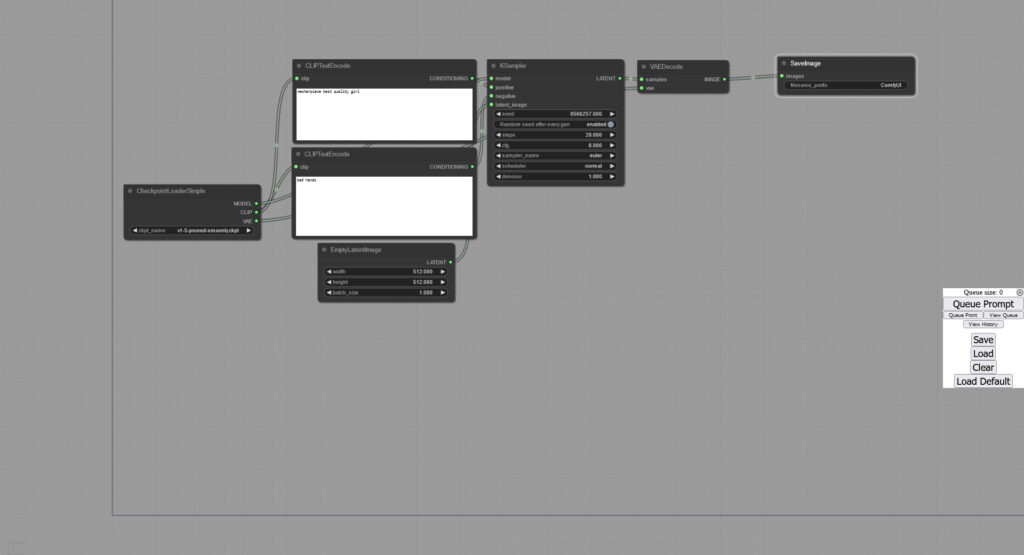
プロンプトは「CLIPTextEncode」に入力します
最終的に右側にある「Ksampler」のpositive/negativeに繋げるので上下はどちらでも問題無いです
「Ksampler」でseedやsteps等を変更します
「EmptyLatentImage」が画像のサイズやbatch_sizeの変更ですね
最後に右端にある「Queue Prompt」をクリックすれば画像が生成されます
後はここに使いたいノードを追加していきます
+VAE
VAEを追加します
右クリック→「Add Node」でノードの追加が出来ます
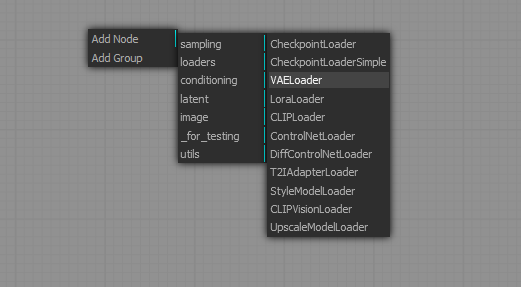
VAEの追加は「loaders」→「VAELoader」です
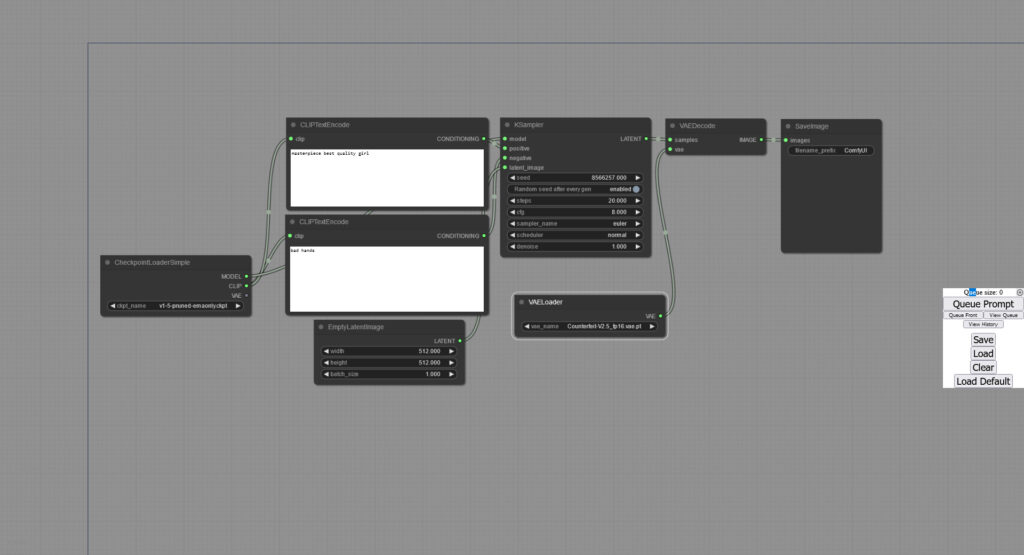
「VAELoader」のvaeから「VAEDecode」のVAEへと繋げればOKです
元々「VAEDecode」に繋がっていた「ChckpointLoader」からは途切れてしまいますが
画像の生成は出来ているので多分大丈夫です
ただ公式ページには詳しいやり方が無かったので恐らくとしか言えないです
(一応メタデータにもあるので多分大丈夫)
+LoRA
次はLoRAの追加です
これはちょっとだけややこしい
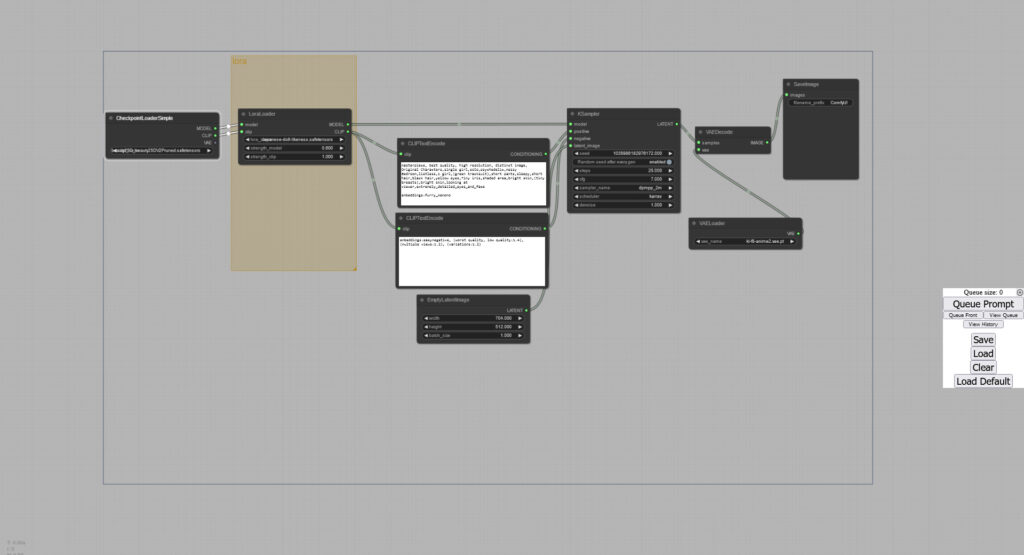
「loaders」→「Loraloader」で追加出来ます
「Loraloader」の処理は「CLIPTextEncode」の前になるみたいですね
接続はこんな感じ
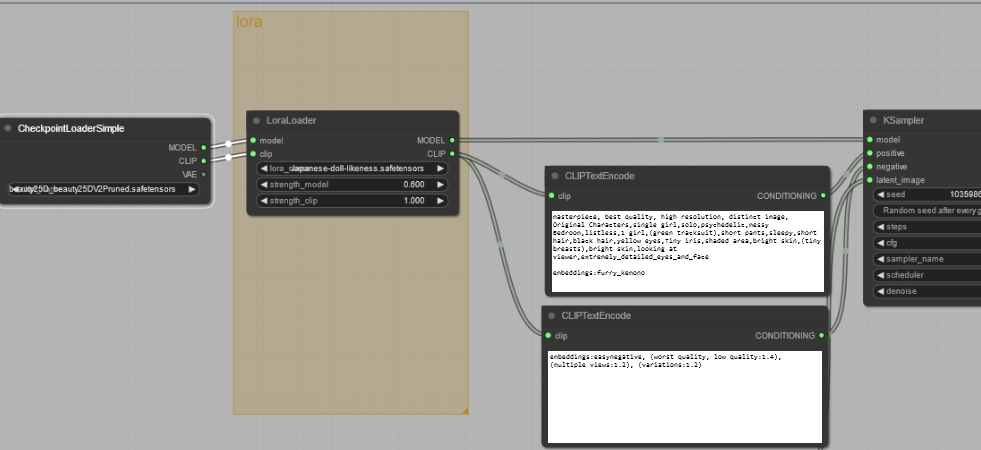
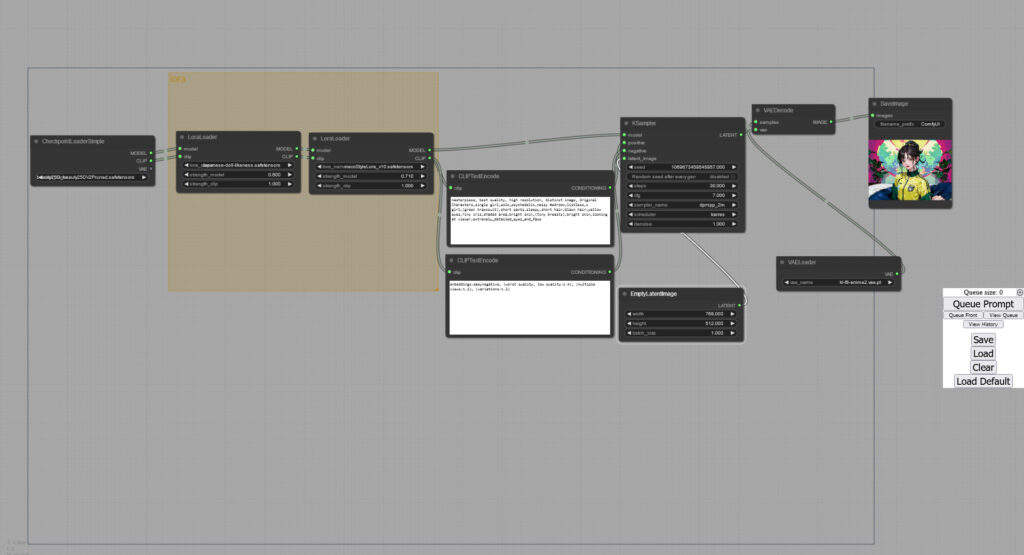
- 「CheckpointLoader」のmodel/clipを「LoraLoader」左側のmodel/clipを接続
- 「LoraLoader」右側のmodelを「Ksampler」のmodelと接続
- 「LoraLoader」右側のclipを「CLIPTextEncode」のClipと接続
後は同じように画像生成するだけでOKです
ちなみに後ろの黄色い枠を作りたい時は「Add Group」をクリックしてください
右下の▼をドラッグすると枠の拡大/縮小が出来ます
枠をダブルクリックするとノードの一覧が出てくるので少し便利かも?
ノードにくっつくと離れないので注意してください
+LoRA+LoRA
LoRAは複数適用出来ます
やり方は簡単
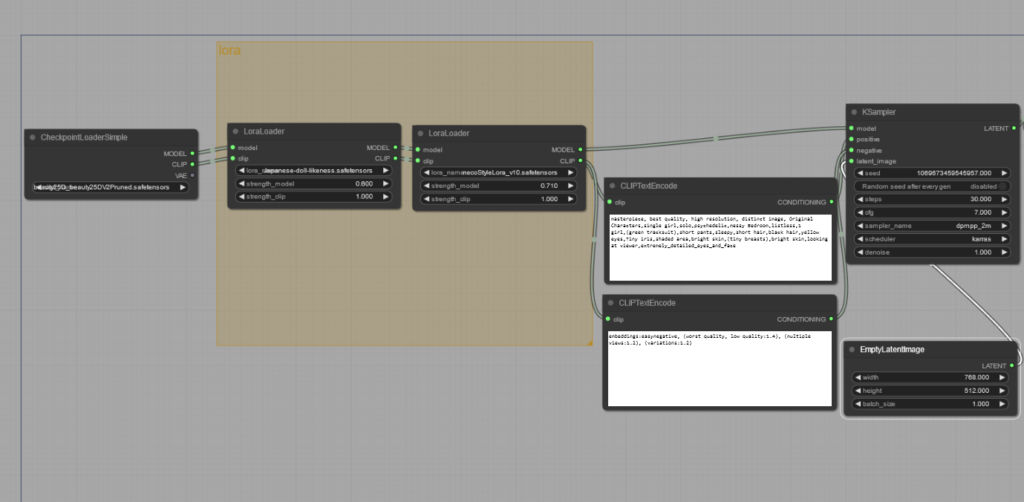
新しく「LoraLoader」を追加して繋げるだけです
全部載せでこんな感じ
img2img
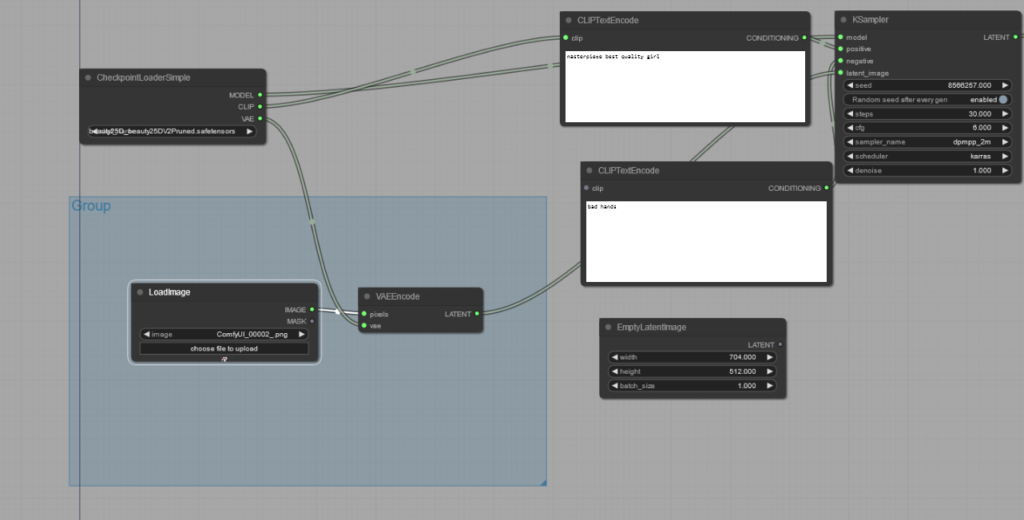
- 「image」から「LoadImage」の追加
- 「latent」から「VAEEcode」の追加(VAEDecodeに似ているので注意)
- 「LoadImage」のimageと「VAEEcode」のpixelsを接続
- 「CheckpointLoader」のvaeと「VAEEcode」のvaeを接続
- 「VAEEcode」のLATENTと「Ksampler」のlatent_imageを接続
これでOKです
その他はt2iと同じになります
PNG info
恐らくwebUIにあるPNG infoは実装されていないと思われます
ブラウザ上に画像をドロップするかLoadで画像をloadするかで
ノードやプロンプトを呼び出すことは出来ますけど
webUIのような使い方は出来ません
ちなみにwebUIで作った画像を読み込んでもノードは呼び出せませんでした
webUIはsendでプロンプトからパラメーターまで呼び出せたのでちょっと不便です
hypernetworks/embeddings
hypernetworksはこれも今のところ使い方がわかりません
embeddingsは問題無く使うことが出来ますが
プロンプトにembeddings:name.ptとを入力する必要があります
拡張子は省略可
未検証
アップスケールモデルやコントロールネットも実装されていますが、今のところ未検証
というか1660superでは実行出来ませんでした
まあwebUIでもコマンドラインで色々やって何とかといったところなので
そんなもんなのかもしれません
なので負荷の高い作業はグラボ等を買い替えてから別で記事を作ります
長くなりそうなので
流石に1660superでは限界みたいですね
予算的には3060 12gbモデルが最有力です