

CLIP modelを変更するとseed等の数値が全て同じでも別の画像
というか画風が結構変わることがわかりました
なので今回はCLIP model毎の違いをまとめてみました
ついでにステップとスケールの最小から最大までの違いも試してみました
正直最小は使う必要は無いです
条件
まずは今回使う画像の条件から
masterpiece, best quality, masterpiece,Face close-up,a girl ,beautiful face,moist eyes,black short hair,Tears,middy uniform,Embarrassed
Negative Prompt/lowres, bad anatomy, bad hands, text error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name,fat- Sampling Steps:28
- Sampling method:Euler
- CFG Scale:12
CLIP model毎の違い




1~9までは結構好みなのかなって感じですけど
10~12は何だか全然違う画像になりましたね
text的には1~5までは割と正確なんですけど
それ以降はちょっと無視されています
なので基本的に1~5までを使って画像を生成するのが良いかもしれません
個人的には3と4が好きですね
ちなみに良く見かける画像のテイストに近いのは2が1番多いと思います
Sampling Steps
次はSampling Stepsの違いを比べてみます
- 最小:1
- デフォルト:20
- 最大:150
僕がよく使うのが30前後ですね
大体20~110くらいが良いと言われています
今回は上3つを比べてみました
ちなみにCLIP modelは3です
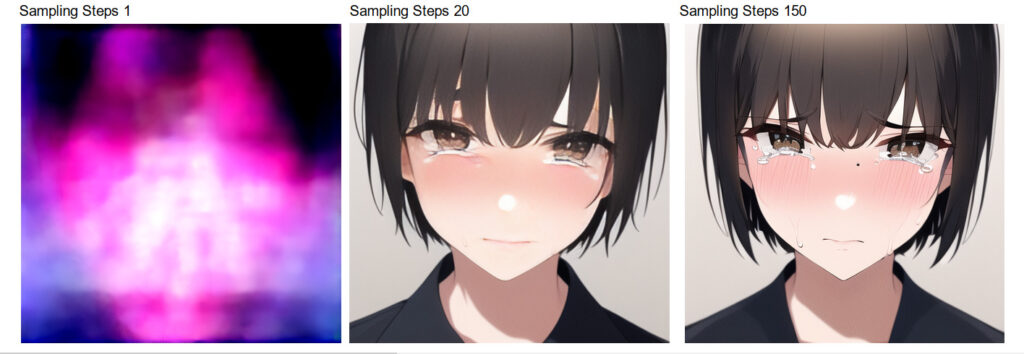
1は流石に論外ですけど20と150でそこまでの違いが無いかなって気がします
確かによく見ると150の方が解像度が高いと言うかキレイなんですけど
かかる時間を考えるとちょっと微妙かなって感じです


まあでも20はちょっとかすれ過ぎですかね
高ければ良い画像が必ず出来る訳でもありませんからこの辺のチョイスは難しいですね
CFG Scale
次はCFG Scaleの違いです
- 最小:1
- デフォルト:7
- 最大:30
Sampling Stepsは28
CLIP modelは3です
こちらは7~12程度が良いらしいです

やはり1はダメみたいですね
7と30だと確かに30の方が色々と書き込みが多い感じがします
ただ個人的には結構7ぐらいのほうが好きだったりします


まあこの辺も好みですかね
ただ無理に最大値の30で作る必要は無いかなって思いました
おまけ
今回使った画像でseedを固定すると結構遊べます
例えばOpen mouthを追加してみると

こんな感じになります

元の画像と比べるてそこまで変化が無い画像が出力出来ます
ただもっと視点を下げようとすると

ちょっと違う人物になってしまいますね
この辺りが課題かなって感じです
ポーズや表情を変えなければ衣装差分のような画像は作れます
あとがき
同じseed値を使ってもクリップやスケール等を変えると全然違った画像になるので
色々試してみると面白いと思います
ただ全く同じ人物をポーズや視点を変えて出力するのはseed値を固定していても難しいです
たまに似たような人物の画像が出来ることもありますけどね
現状は服装を変更するくらいですね
こんかいはここまでです
以上