

前回CLIP model毎の違いを比べてみましたが
Sampling methodも変更すると結構画像が変わってくるので比べてみました
よければ前回の記事も合わせて見て下さい↓
【Stable Diffusion】CLIP model毎の違いとステップ&スケール
今回もNovel AIのmodelを使ってますが
恐らくmodelでも違ってくると思うので参考程度に留めておいてください
条件
a girl standing,beautiful face,moist eyes,black short hair,Tears,middy uniform,Embarrassed
Negative prompt/lowres, bad anatomy, bad hands, text error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name,fat
Steps:28CFG scale:12 Size:512x704 Clip skip:3今回は少しサイズを変えて縦長にしてみました
ポーズを付ける時なんかはこれくらいのサイズの方が良い感じの画像になる気がします
ただ顔のアップは生成時間を考えると512×512の方が良いと思います
Sampling method
Sampling methodはこの部分です
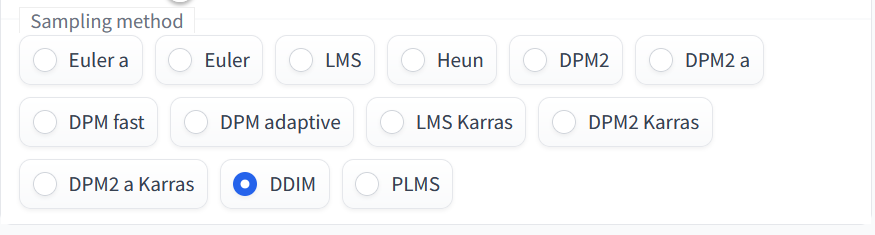
普段は「Euler a」や「Euler」を使う事が多いですね
で実際に比較した画像がこちらになります




まず「DPM adaptive」と「PLMS」僕の環境では画像が生成出来ませんでした
中にはまるで使えないものも混じっていますが
どれも割と好みかなといった印象です
「Euler a」と「DPM a」の2つだけ他とちょっと違うみたいですね
拡大すると粗が目立ちますが結構この画像が好きです

でもどの画像も割と似通ったキャラクターにはなっていると思いますので
CLIP modelほどの違いは無さそうです
恐らくこの画像を生成したプロンプトではポーズ的な指定が無かったので
ポーズがまちまちなんだと思います
またimg2imgでも「LMS」と「LMS karras」は変な感じになっていたので
このmodelでは「LMS系」は良く無いのかもしてません
img2imgでSampling methodを変えると例えば同一のポーズで服装が少し変わる感じでした
もし気に入った画像があればimg2imgで色々と試してみると面白いかもしれません
もっともプロンプトが無ければ同じ画像は作れませんので
何となくそれっぽいプロンプトでちょっと似た画像を作る感じにはなってしまいますが
プロンプトの探し方
プロンプトが思い付かない時に使えそうなサイトを紹介します
まあ正直イマイチではあるんですけど
構図なんかの参考になるかもしれません
MagicPrompt
まずは「MagicPrompt」からです
https://huggingface.co/spaces/Gustavosta/MagicPrompt-Stable-Diffusion
こちらは文章を入力するとプロンプトを出力してくれます
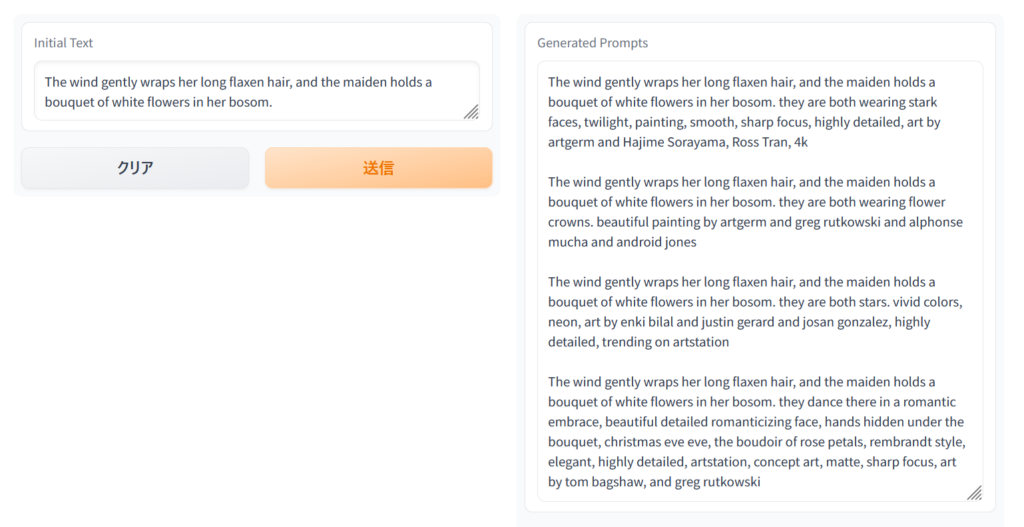
Initial Textに英語で文章を入力すると隣にいくつかプロンプトが出力されます
これをプロンプトにぶち込めばOKです
良い感じの文章が思いつかなかったのである歌の歌詞を一部入力してみました
一応4つ全て生成してみましたが
う~んって感じです

何かセンスが洋って感じですね
上手な絵だとは思いますけど求めてる感じでは無いです
4枚目は結構ありかもしれませんが

ダメですね
腕がいかれていました
KREA
お次は「KREA」です
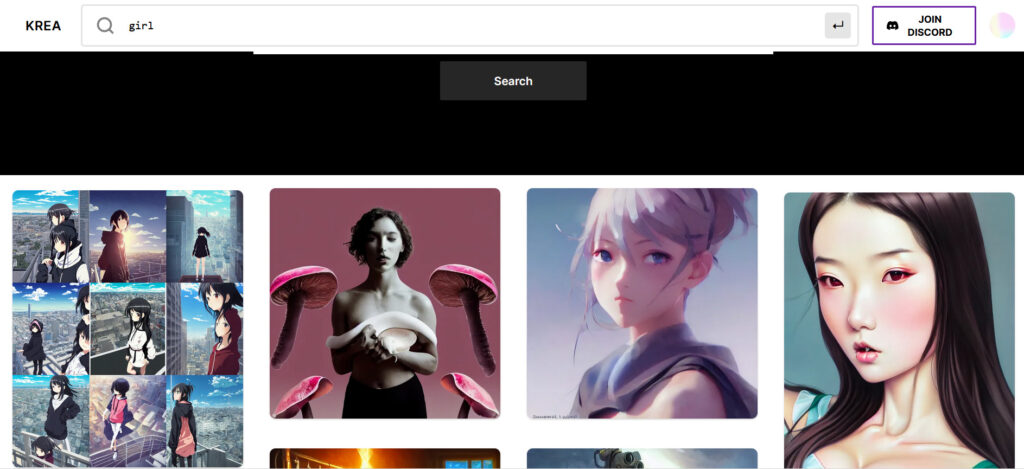
検索に好きな単語を入力すると画像が表示されます
画像をクリックするとプロンプトが書かれているのでそれをweb UI等で入力すれば良いって感じです
試しに1番マトモそうな左から2番目のプロンプトを入力してみました

modelの違いかはわかりませんが全く違う画像になっていますね
まあseed諸々も違うので仕方ないと言えば仕方無いですが
どちらもまだ簡単に試しただけなのでもうちょい色々試してみます
特に「MagicPrompt」の方は結構良さそうな気がしますね
あとがき
Sampling methodは今回作った画像ではこの結果といった感じでして
別の画像で試した時は「DDIM」が1番良さそうだったパターンもあります
気に入った画像が出来た時はSampling methodを変えてみるともっと良い画像になるかもしれません
是非試してみて下さい
以上