
少し前ですけどStable Diffusionがバージョンアップされていたのでweb UIで使えるようにしました
まあ正直ホントに適用されているのか怪しいところですけどね
2.1のものと見られるモデルはそんなに良くは無いみたいです
なので.yamlファイルが他のモデルにも適用されているかどうかが重要なんですけど
ちょっと知識が足りませんでしたね
一応前のverで作った画像と同一プロンプトで比較してみましたが
まだ何とも言えないところです
導入方法
基本的にはモデルをダウンロードする時と同じです
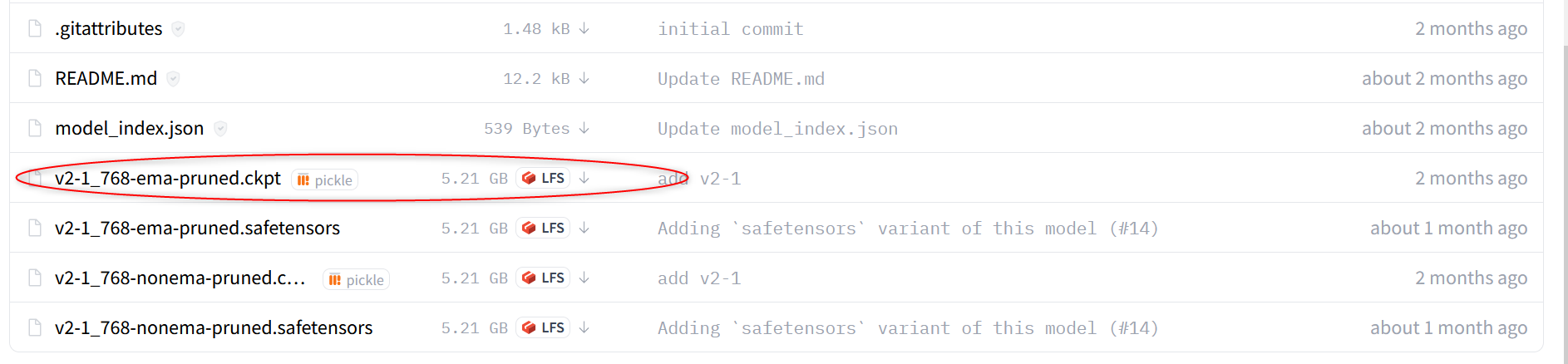
https://huggingface.co/stabilityai/stable-diffusion-2-1/tree/main
↑のリンク先からv2-1_768-ema-pruned.ckptファイルをダウンロードしてください
で、yamlファイル何ですけど↓のリンクを「名前を付けて保存」してください
リンク
そうするとv2-inference-v.yamlが保存されるハズです
あとはダウンロードしたファイルをモデルが保存されているフォルダにぶち込み
yamlのファイル名をモデルと同じ名前に変更すればOKです
エラー
僕の場合何ですけど実際画像を作ろうとしたらエラーがおきました
エラーコードはこんな感じ
modules.devices.NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.恐らくグラボのスペックが足りないってことだと思います
で設定を変えるか--no-halfコマンドライン引数を使用しろってことみたいです
--no-halfコマンドライン引数は確かwebui-user.batを書き換えるってことだったとハズ
今回は設定を変更するだけで大丈夫でしたがダメだった場合
【Stable Diffusion】web UI AUTOMATIC1111版をローカル環境で動かしたい「成功」+merge-modelsでmodelを混ぜるにwebui-user.batを書き換える方法を解説しているので確認してみてください
設定変更はUpcast cross attention layer to float32にチェックを入れるだけです

このあとは問題無く画像生成が出来ています
画像比較
実際どうなったのか比較してみます
元画像はこちら

この画像と同じプロンプトで作ってみます

まあデフォルトのモデル確かにこんな感じだった気がします
二次元イラストに特化したモデルでも無いのでこんなもんなんでしょう

これは2.1を導入したあとにAnything-V3.0で作った画像です
どの程度変わったのかわかりませんが何とも構図が微妙になってしまっている印象ですね
もう少しAnything-V3.0で比較してみます
画像は芋ジャージから




上からseed値固定で作成しているので大体同じ画像が出来るハズです




微妙に変わっているみたいですね
極端に良くなったようにも悪くなったようにも見えません
あとがき
ちゃんと導入出来たかどうかわかりませんが
少し変わってはいるみたいですね
まあ僕の設定がおかしいのか起動し直すと
同一条件でも少し違った画像が出来ることが多いので何とも言えません
以上