

ControlNetの各モデルを比較してみました
タイトルにも書いてありますが、結局二次元イラストで使いやすいのはopenposeになります
写真から作る場合はほとんど一択になるかなーってところですね
一応mlsd、scribble、segmentationも悪くは無いんですけど、少し使い辛いと思います
depthは使いかた次第で面白くなりそうですけど、写真から簡単に作るってなると微妙ですね
結構手間がかかります
ControlNetについての導入方法等をまとめた記事もあるのでそちらも参考にしてください
Stable Diffusion web UI 新拡張機能「ControlNet」
ControlNetで使うカラフル棒人間を簡単に作れる Blenderアドオン 導入&使用方法紹介
設定
参考画像

今回はフリー写真を借りてきました
パリピな感じの女性ですね
プロンプトからこのポーズを作るのはなかなか厳しいと思います
どちらにしろ複雑なプロンプトを考えないといけません
プロンプト
(((masterpiece))), (((best quality))), ((ultra-detailed)), (digital art), (detailed light),((an extremely delicate and beautiful)),messy Bedroom,listless,1 girl,(green tracksuit),sleepy,short hair,bob cut,black hair,yellow eyes,gray scale,((shaded area)),bright skin,(tiny breasts),fish eye,looking at viewer,from below,[extremely_detailed_eyes_and_face]<hypernet:furry:1.0>
Negative prompt: lowres, bad hands, text,error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name,fat,red face,nipple,nude,large breasts
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 12,Face restoration: GFPGAN, Size: 704x512,Clip skip: 2,models anything-v4.5 ,VAE anything-v4.0少し長いですね
ControlNetを上手く使えば今後は短いプロンプトで済みそうです
ただネガティブプロンプトはそこまで変わらないかもしれませんね
あと僕のグラボだと性能的に結構厳しかったのでLow VRAMを使っています
多分そこまで違いは無いと思いますけど、もしかしたら品質は少し悪くなっているのかもしれません
「RuntimeError: CUDA out of memory.・・・」こんなメッセージが出たらLowにいれて試してみてください
canny

写真に忠実な画像になっているみたいですね
ちょっと不気味なのはfurryの影響かと思います
どうやら下半身は認識されていないみたいで、テケテケ状態になってしましました
元の画像が大き過ぎたのか、ボヤけているのが悪いのか
depth

これはシルエット的なもので認識しているのかな?
depthを翻訳すると「深度」ってことらしいですけど、正直よくわかりませんね
人物写真からdepthを使って画像生成するのは厳しいかなと思います
ただ背景のみを作るなら良いのかもしれません

こんな感じで背景や小物をdepthで作成して
openposeあたりで人物を作れば良い画像になるんじゃないでしょうか?
まあ合成をする必要があるのでStableDiffusion上で完結出来なくなってしまいますけど
今回はBlenderで簡単にdepth画像を作ってみましたが、人が写っていない写真でも可能だと思います
ただBlenderで作れば自分の理想的な背景を作ることも出来るので、頑張ってみる価値はあるかもしれません
無料のアセットも充実しているので結構簡単に作れます、よほど拘らなければ
ちょっと面白そうなのでこれはまた別でまとめようと思います
hed
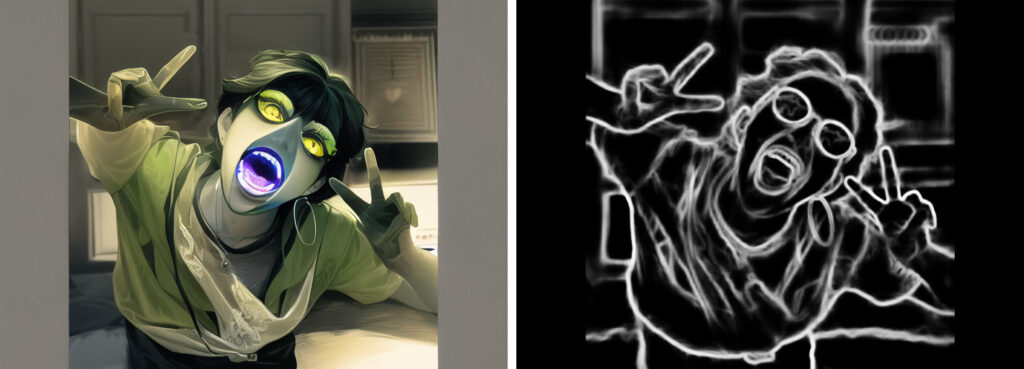
頭かと思ったら綴りが違いました、どういった意味なのかはわかりません
何か良くわからないけど版画みたいになっていますね
生成画像はモンスター感が出ていますが、これもfurryの影響がありそうなので何とも言えません
認識している範囲はcannyと変わらないけど雰囲気は随分違いますね
どう使えば良いのか全く思いつきません
mlsd

ようやく二次元イラスト的な画像になりました
人をくり抜いたところにキャラクターを生成しているのかな?
ポーズは全然違うみたいです
うーん背景だけを利用したい時に使えるか?
でも空いたところにどんな感じで画像が生成されるのか予想がし辛いし、やっぱり良くわかりません
何枚か作ってみても結構ランダムでしたし



ちょっとバラツキ過ぎですね
魚は何?
normal map

cannyやhedと認識している範囲というか、参照にしているデータ?は多少違うみたいですけど
あんま出来上がっている画像に違いが無いような気がしますね
他よりも多少マシなような感じはしますけど
これくらいならまだギリギリ使えるレベルかな?
ただプロンプト次第なところもあって、試しにケモノ系を出力してみたんですけど

何かバランスが悪すぎます
やけにマッシブな画像になってしまいました
openpose

やっぱりopenposeが1番安定していますね
ただピースサインをしている画像は1枚も出来ませんでした
指まではしっかり認識していないのかもしれません
少し角度が違うみたいですが、from belowが反映されている可能性もありますね
多少の調整はききそうですね
openpose_hand

そんなに違いは無いです
handになっていますけど、別に手をしっかり描いてくれるわけじゃないようです
出力された棒人間には確かに指があるみたいですけど、結構グチャグチャですね
一応指もしっかり色分けすれば自作出来るようです
今のところそこまでする価値は無いかも
scribble

scribbleは落書きって意味らしいです
正直何がどうなっているのか良くわかりません
結構好きな画像ですけどね

重ねるとこんな感じ
合っているようなそうでも無いような・・・
fake_scribble

なんだろう
アウトラインとかそんな感じですか?
ポーズはしっかりと認識しているようなので、写真をイラストに変換するには結構良いかもしれません
画像の出来次第かもしれませんけどね
この画像は個人的には好きです
segmentation

シルエットがしっかりと画像になっているようですね
これは使える場面はありそうです
色分けされているようなので、条件がわかれば自作出来るかもしれません
上手いこと書き分けている画像を見たような記憶があります